Capítulo 6: Introducción al Machine Learning con Python
¿Qué es el Machine Learning?
El Machine Learning (Aprendizaje Automático) es una rama de la Inteligencia Artificial que proporciona a los sistemas la capacidad de aprender automáticamente y mejorar a partir de la experiencia sin ser programados explícitamente para cada tarea.
En palabras de Arthur Samuel, quien acuñó el término en 1959, el Machine Learning es "el campo de estudio que da a las computadoras la capacidad de aprender sin ser programadas explícitamente".

El Machine Learning se ha convertido en una herramienta indispensable en la ciencia de datos, permitiendo:
- Predicción de resultados basados en datos históricos
- Identificación de patrones no evidentes para el análisis humano
- Automatización de decisiones basadas en datos
- Procesamiento de grandes volúmenes de información a velocidades imposibles para humanos
- Adaptación continua a nuevos datos y situaciones cambiantes
Principales Tipos de Machine Learning
El aprendizaje automático se divide generalmente en tres categorías principales:
.png?width=1800&height=941&name=Machine%20learning%20(1).png)
Aprendizaje Supervisado
En el aprendizaje supervisado, el algoritmo aprende de datos etiquetados (ejemplos de entrada-salida). El objetivo es aprender una función que, dada una entrada, predice correctamente la salida.
Principales tareas:
- Regresión: Predicción de valores continuos (ej. precio de una casa)
- Clasificación: Asignación a categorías discretas (ej. spam/no spam)
Aprendizaje No Supervisado
En el aprendizaje no supervisado, el algoritmo aprende patrones a partir de datos no etiquetados, sin tener una "respuesta correcta" predefinida.
Principales tareas:
- Clustering: Agrupamiento de datos similares
- Reducción de dimensionalidad: Simplificación de datos manteniendo sus características esenciales
- Detección de anomalías: Identificación de valores atípicos
Aprendizaje por Refuerzo
En el aprendizaje por refuerzo, un agente aprende a tomar decisiones mediante la interacción con un entorno, recibiendo recompensas o penalizaciones según sus acciones.
Flujo de Trabajo en un Proyecto de Machine Learning
Esta sección está basada en el Apéndice B (Machine Learning Project Checklist) del libro Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems 2nd Edition de Aurélien Géron, con algunas adaptaciones y adiciones personales basadas en mi experiencia y en otros materiales didácticos.
El libro está acompañado por un repositorio con Jupyter Notebooks: https://github.com/ageron/handson-ml2
Un proyecto de Machine Learning sigue un proceso estructurado que permite desarrollar modelos efectivos y confiables. A continuación, presento una guía paso a paso que puede servir como lista de verificación para tus proyectos.
1. Definición del Problema
El primer paso es entender claramente qué problema estamos tratando de resolver:
- Definir el objetivo en términos del negocio o aplicación
- Identificar cómo se usará la solución
- Revisar soluciones actuales (si las hay)
- Enmarcar el problema correctamente: supervisado/no supervisado, en línea/fuera de línea, etc.
- Establecer las métricas de desempeño apropiadas
- Determinar el desempeño mínimo necesario para alcanzar el objetivo
- Identificar problemas similares para reutilizar experiencias o herramientas
- Listar supuestos iniciales y verificarlos si es posible
2. Obtención de los Datos
Una vez definido el problema, debemos obtener los datos necesarios:
- Identificar los datos necesarios y la cantidad requerida
- Documentar las fuentes de los datos
- Verificar limitaciones legales y obtener autorizaciones si es necesario
- Calcular el espacio de almacenamiento requerido
- Obtener los datos y convertirlos a un formato manipulable
- Proteger información confidencial (anonimizar datos si es necesario)
- Verificar el tamaño y tipo de datos (series temporales, datos geoespaciales, etc.)
- Separar un conjunto de prueba y reservarlo sin manipular
3. Exploración de los Datos (EDA)
El análisis exploratorio de datos nos permite entender mejor la información con la que contamos:
- Crear una copia de los datos para explorarlos
- Utilizar Jupyter Notebooks para documentar la exploración
- Estudiar cada atributo y sus características:
- Tipo de dato (categórico, numérico, texto, etc.)
- Porcentaje de valores faltantes
- Ruido y tipos de ruido presentes
- Utilidad potencial para el proyecto
- Distribución (gaussiana, uniforme, logarítmica, etc.)
- Identificar los atributos objetivo (target) en proyectos supervisados
- Visualizar los datos para detectar patrones
- Estudiar correlaciones entre atributos
- Identificar transformaciones posibles
- Documentar todos los hallazgos
Existen varias librerías en Python que facilitan el EDA:
# Ejemplos de librerías para EDA
import pandas as pd
import pandas_profiling # Generación automática de reportes EDA
import sweetviz # Visualizaciones automáticas
import dtale # Interfaz interactiva para exploración
import matplotlib.pyplot as plt
import seaborn as sns
# Ejemplo básico
# Cargar datos
df = pd.read_csv('datos.csv')
# Resumen estadístico
print(df.describe())
# Verificar valores nulos
print(df.isnull().sum())
# Crear un informe completo con pandas_profiling
from pandas_profiling import ProfileReport
profile = ProfileReport(df, title="Informe de Datos")
profile.to_file("informe_eda.html")
4. Preparación de los Datos
Esta fase es crucial para exponer mejor los patrones en los datos y prepararlos para los algoritmos de ML:
- Limpieza de datos:
- Eliminar registros duplicados
- Corregir o eliminar valores atípicos (cuando sea apropiado)
- Manejar valores faltantes (imputación o eliminación)
- Selección de atributos (Feature Selection):
- Descartar atributos sin información útil
- Eliminar redundancias
- Ingeniería de atributos (Feature Engineering):
- Discretizar variables continuas cuando sea útil
- Descomponer atributos complejos (fechas, categorías, etc.)
- Aplicar transformaciones matemáticas (log, sqrt, potencias)
- Crear nuevos atributos derivados
- Escalado de atributos (Feature Scaling):
- Estandarización (z-score)
- Normalización (Min-Max)
# Ejemplo de preparación de datos en Python
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# Definir transformadores para variables numéricas
num_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
# Definir transformadores para variables categóricas
cat_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
# Combinar transformadores
preprocessor = ColumnTransformer(
transformers=[
('num', num_transformer, numerical_cols),
('cat', cat_transformer, categorical_cols)
])
# Crear un pipeline para la preparación de datos
data_pipeline = Pipeline(steps=[('preprocessor', preprocessor)])
# Aplicar las transformaciones
X_processed = data_pipeline.fit_transform(X)
5. Selección de Modelos
En esta fase, evaluamos diferentes algoritmos para identificar los más prometedores:
- Entrenar modelos rápidos de diferentes categorías con parámetros estándar
- Medir y comparar su desempeño usando validación cruzada
- Analizar variables significativas para cada algoritmo
- Estudiar los tipos de errores que cometen los modelos
- Realizar rápidas iteraciones de ingeniería de atributos
- Seleccionar 3-5 modelos prometedores, preferiblemente con diferentes tipos de errores
Validación Cruzada (Cross-Validation)
Al evaluar diferentes modelos, es fundamental utilizar validación cruzada para obtener una estimación confiable de su rendimiento. Esta técnica divide los datos en varios subconjuntos o "pliegues" (folds) y realiza múltiples iteraciones de entrenamiento y evaluación.
En la validación cruzada de k-pliegues (k-fold cross-validation), el proceso es el siguiente:
- Se divide el conjunto de datos en k subconjuntos de igual tamaño
- Para cada uno de los k subconjuntos:
- Se entrena el modelo usando los k-1 subconjuntos restantes
- Se evalúa el modelo en el subconjunto reservado
- Se promedian las k métricas de rendimiento para obtener una estimación más robusta
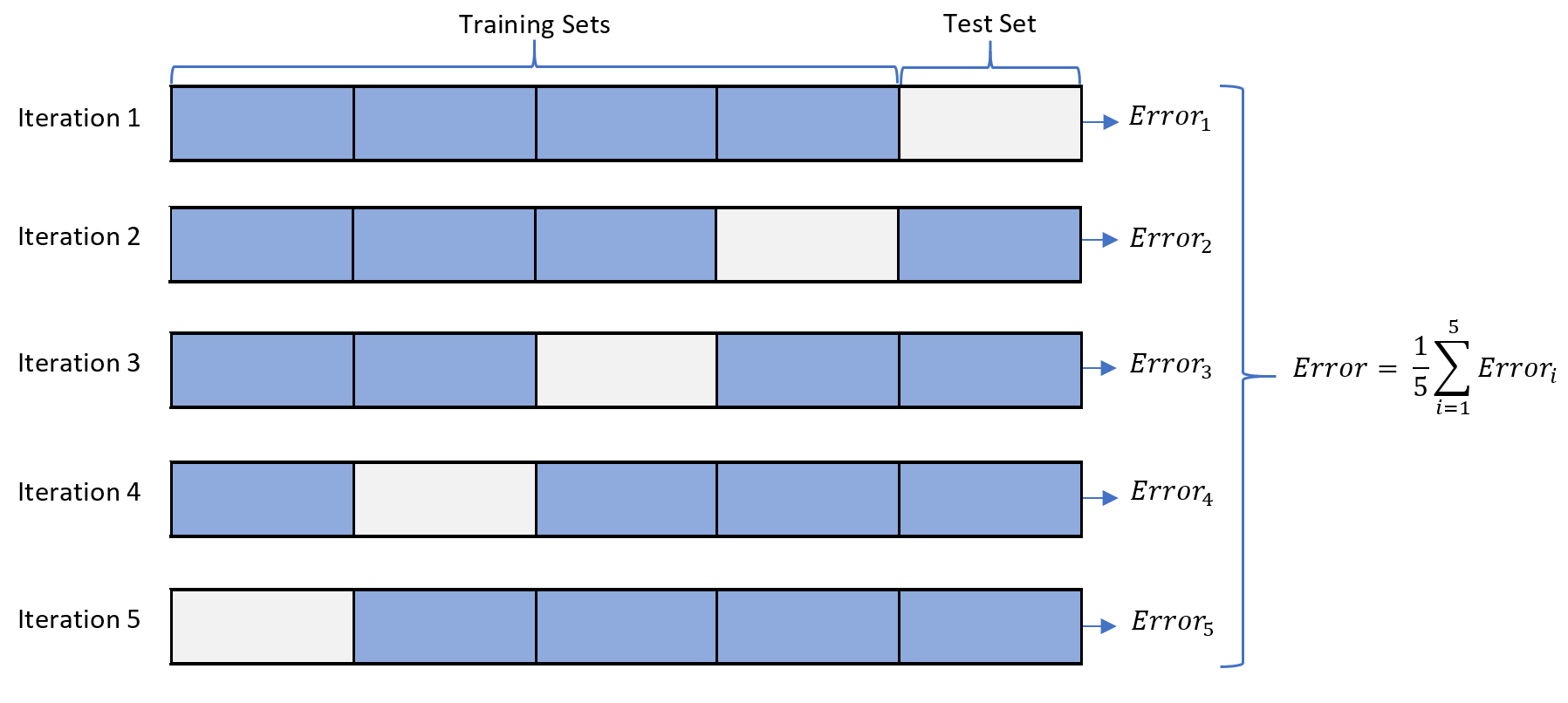
- El conjunto de datos es pequeño
- Se desea maximizar el uso de los datos disponibles
- Se busca una estimación más precisa del rendimiento del modelo
# Ejemplo de evaluación de modelos en Python
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
# Definir modelos a evaluar
models = {
'LogisticRegression': LogisticRegression(),
'RandomForest': RandomForestClassifier(),
'SVC': SVC(),
'KNeighbors': KNeighborsClassifier(),
'DecisionTree': DecisionTreeClassifier()
}
# Evaluar cada modelo con validación cruzada
results = {}
for name, model in models.items():
cv_scores = cross_val_score(model, X_train, y_train, cv=5, scoring='accuracy')
results[name] = {
'mean_score': cv_scores.mean(),
'std_score': cv_scores.std()
}
print(f"{name}: {cv_scores.mean():.4f} (±{cv_scores.std():.4f})")
6. Afinamiento de Modelos
Una vez identificados los modelos prometedores, optimizamos sus hiperparámetros:
- Ajustar hiperparámetros mediante validación cruzada
- Tratar las transformaciones de datos como hiperparámetros cuando sea apropiado
- Preferir búsqueda aleatoria (random search) sobre búsqueda en cuadrícula (grid search) para espacios grandes de hiperparámetros
- Explorar métodos de ensamble combinando los mejores modelos
- Evaluar el modelo final en el conjunto de prueba para estimar el error de generalización
Optimización de Hiperparámetros
Un paso crucial en el afinamiento de modelos es la optimización de hiperparámetros, que consiste en encontrar la configuración óptima de parámetros externos al modelo que afectan su rendimiento y capacidad de generalización.
Los hiperparámetros son configuraciones que no se aprenden durante el entrenamiento, sino que deben especificarse previamente. Ejemplos comunes incluyen:
- Árboles de decisión/Random Forest: profundidad máxima, número mínimo de muestras por nodo, número de árboles
- SVM: tipo de kernel, parámetro de regularización C, gamma
- Redes neuronales: tasa de aprendizaje, número de capas ocultas, unidades por capa, dropout rate
- Gradient Boosting: tasa de aprendizaje, número de estimadores, profundidad de árboles
Existen principalmente dos enfoques para la búsqueda de hiperparámetros:
| Grid Search | Evalúa exhaustivamente todas las combinaciones posibles de valores de hiperparámetros especificados. Es completa pero computacionalmente costosa cuando hay muchos parámetros. |
| Random Search | Muestrea aleatoriamente combinaciones del espacio de hiperparámetros. Suele ser más eficiente que Grid Search, especialmente cuando no todos los hiperparámetros son igualmente importantes. |
# Ejemplo de afinamiento de hiperparámetros
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import randint, uniform
# Definir espacio de búsqueda para Random Forest
param_dist = {
'n_estimators': randint(100, 500),
'max_depth': randint(5, 30),
'min_samples_split': randint(2, 20),
'min_samples_leaf': randint(1, 10),
'max_features': ['auto', 'sqrt', 'log2', None]
}
# Crear el modelo base
rf = RandomForestClassifier()
# Configurar la búsqueda aleatoria
random_search = RandomizedSearchCV(
rf,
param_distributions=param_dist,
n_iter=100,
cv=5,
scoring='accuracy',
n_jobs=-1,
verbose=1
)
# Ejecutar la búsqueda
random_search.fit(X_train, y_train)
# Obtener y mostrar los mejores parámetros
print("Mejores parámetros:", random_search.best_params_)
print("Mejor puntuación:", random_search.best_score_)
# Evaluar en el conjunto de prueba
best_model = random_search.best_estimator_
test_score = best_model.score(X_test, y_test)
print(f"Puntuación en el conjunto de prueba: {test_score:.4f}")
7. Interpretabilidad del Modelo
Entender por qué y cómo funciona el modelo es esencial para generar confianza y detectar posibles problemas:
- Identificar las características más importantes que influyen en las predicciones
- Analizar la contribución de cada característica a las predicciones
- Evaluar las consecuencias de predicciones erróneas
- Examinar los tipos de errores que comete el modelo
- Establecer métodos para monitorear los errores en producción
- Entender las causas de los errores:
- Valores atípicos
- Clases desbalanceadas
- Errores en los datos de entrada
- Limitaciones del algoritmo
# Ejemplo de análisis de interpretabilidad
import shap
import matplotlib.pyplot as plt
from sklearn.inspection import permutation_importance
# Para modelos basados en árboles, podemos ver directamente la importancia de características
feature_importances = best_model.feature_importances_
feature_names = X_train.columns
# Visualizar importancia de características
plt.figure(figsize=(10, 6))
sorted_idx = np.argsort(feature_importances)
plt.barh(range(len(sorted_idx)), feature_importances[sorted_idx])
plt.yticks(range(len(sorted_idx)), np.array(feature_names)[sorted_idx])
plt.xlabel('Importancia de Característica')
plt.title('Importancia de Características del Modelo')
plt.tight_layout()
plt.show()
# Para análisis más avanzados, podemos usar SHAP
explainer = shap.TreeExplainer(best_model)
shap_values = explainer.shap_values(X_test)
# Resumen de valores SHAP
shap.summary_plot(shap_values, X_test, feature_names=feature_names)
# Gráfico de dependencia para ver relaciones específicas
shap.dependence_plot("feature_name", shap_values, X_test)
8. Presentación de la Solución
Comunicar efectivamente los resultados es clave para el éxito del proyecto:
- Documentar todo el proceso y las decisiones tomadas
- Crear una presentación clara que resalte el panorama general
- Explicar cómo la solución cumple con los objetivos iniciales
- Destacar hallazgos interesantes descubiertos durante el proceso
- Describir lo que funcionó y lo que no funcionó
- Enumerar supuestos y limitaciones del modelo
- Comunicar hallazgos clave mediante visualizaciones efectivas
9. Despliegue, Monitoreo y Mantenimiento
La implementación en producción y el mantenimiento continuo son esenciales para el éxito a largo plazo:
- Preparar la solución para producción:
- Conectar a fuentes de datos en producción
- Desarrollar pruebas unitarias
- Optimizar el rendimiento
- Implementar monitoreo continuo:
- Verificar el rendimiento en tiempo real
- Configurar alertas para fallos o degradación
- Prevenir la degradación gradual:
- Los modelos tienden a "pudrirse" con el tiempo a medida que los datos evolucionan
- Establecer métricas para detectar cuándo es necesario reentrenar
- Controlar la calidad de los datos de entrada para detectar anomalías o cambios
- Automatizar el reentrenamiento con nuevos datos (Continuous Training and Deployment)
# Ejemplo de cómo guardar un modelo para producción
import joblib
from sklearn.pipeline import Pipeline
# Crear un pipeline completo que incluya preprocesamiento y modelo
full_pipeline = Pipeline([
('preprocessor', preprocessor), # El preprocesador definido anteriormente
('model', best_model) # El mejor modelo encontrado
])
# Entrenar el pipeline completo
full_pipeline.fit(X_train_raw, y_train) # Datos sin preprocesar
# Guardar el pipeline para uso en producción
joblib.dump(full_pipeline, 'modelo_produccion.pkl')
# Ejemplo de carga y uso del modelo en producción
loaded_model = joblib.load('modelo_produccion.pkl')
predictions = loaded_model.predict(new_data) # Se puede usar directamente con datos sin procesar
Scikit-learn: La Librería Principal para Machine Learning en Python
Para implementar este flujo de trabajo, scikit-learn es la herramienta más utilizada en Python. Ofrece una API consistente para diferentes algoritmos y utilidades de preprocesamiento, evaluación y selección de modelos.

En los próximos capítulos exploraremos en detalle cómo utilizar scikit-learn y otras librerías para implementar cada paso de este flujo de trabajo, centrándonos en regresión, clasificación y clustering.
Conceptos Clave Aplicados en Scikit-learn
Para trabajar efectivamente con Machine Learning en Python, es fundamental comprender dos conceptos centrales en scikit-learn: la diferencia entre transformadores y estimadores, y cómo utilizar pipelines para crear flujos de trabajo eficientes y reproducibles.
Transformadores vs Predictores en Scikit-learn
En el ecosistema de scikit-learn, todos los objetos son estimadores, pero existen diferentes tipos especializados que cumplen funciones específicas en el flujo de trabajo de Machine Learning.

Transformadores (Transformers)
Los transformadores son un tipo especial de estimador que se usa para transformar datos. Implementan métodos adicionales para modificar los datos de entrada.
Características principales de los transformadores:
- Método
fit(X): Aprende parámetros para la transformación a partir de los datos - Método
transform(X): Aplica la transformación aprendida a nuevos datos - Método
fit_transform(X): Combina fit() y transform() en una sola operación - Se usan para preprocesamiento: Escalado, codificación, reducción de dimensionalidad, etc.
Predictores (Predictors)
Los predictores son estimadores que implementan el método predict() para hacer predicciones sobre nuevos datos. A diferencia de los transformadores que modifican los datos, los predictores aprenden patrones y relaciones para generar predicciones.
Características principales de los predictores:
- Método
fit(X, y): Aprende patrones de los datos de entrenamiento y sus etiquetas - Método
predict(X): Genera predicciones para nuevos datos basándose en el conocimiento aprendido - Método
score(X, y): Evalúa la calidad de las predicciones comparándolas con las etiquetas verdaderas - Se usan para entrenar modelos en tareas de predicción: Clasificación, regresión, clustering, etc.
Pipelines en Scikit-learn
Un Pipeline en scikit-learn es una herramienta que permite encadenar múltiples pasos de procesamiento y modelado en un flujo secuencial. Esta es una de las características más poderosas de scikit-learn para crear workflows reproducibles y eficientes.

¿Por qué usar Pipelines?
Los pipelines resuelven varios problemas comunes en Machine Learning:
- Prevención de Data Leakage: Aseguran que las transformaciones se apliquen correctamente en validación cruzada
- Reproducibilidad: Encapsulan todo el flujo de trabajo en un objeto reutilizable
- Simplicidad: Reducen la complejidad del código y facilitan el mantenimiento
- Optimización conjunta: Permiten la búsqueda de hiperparámetros en todo el pipeline
- Facilidad de despliegue: Un pipeline entrenado puede guardarse y utilizarse directamente en producción
Estructura de un Pipeline
Un pipeline está compuesto por:
- Pasos intermedios: Deben ser transformadores (implementar
fit()ytransform()) - Paso final: Puede ser cualquier estimador (transformador, predictor, etc.)
- Nombres de pasos: Cada paso tiene un nombre único para poder referenciarlo
Material de Práctica
Para consolidar los conceptos aprendidos en este capítulo, te invito a realizar el siguiente ejercicio:
- Contrucción de un proyecto de Machine Learning - Aumenta tu capacidad de análisis con este ejercicio práctico.
Referencias
Para profundizar en Machine Learning con Python, recomendamos consultar estos valiosos recursos:
- Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, un completo libro de Aurélien Géron que cubre desde los fundamentos hasta técnicas avanzadas de Machine Learning, con ejemplos prácticos y código en Python.
- Machine Learning in Python: Step-By-Step Tutorial, un tutorial práctico de Jason Brownlee que guía a través del proceso completo de desarrollo de un proyecto de machine learning con Python, desde la carga de datos hasta la evaluación del modelo.
- How to Master Python for Machine Learning from Scratch, una guía detallada de Shivam Bajpai especialmente útil para principiantes que desean aprender Python específicamente para aplicaciones de machine learning, con enfoque en los conceptos fundamentales.