
Todo lo que siempre quisiste saber sobre la visión por computadora
Published:

Ejemplo de segmentación de imagen en visión por computadora
Uno de los campos más avanzados y fascinantes de la inteligencia artificial es la visión por computadora, que casi seguramente has experimentado de muchas maneras sin saberlo. Aquí tienes una mirada a lo que es, cómo funciona y por qué es tan impresionante.
La visión por computadora es el campo de la informática que se centra en replicar partes de la complejidad del sistema de visión humano y permitir que las computadoras identifiquen y procesen objetos en imágenes y videos de la misma manera que lo hacen los humanos. Hasta hace poco, la visión por computadora solo funcionaba con capacidad limitada.
Gracias a los avances en inteligencia artificial y las innovaciones en aprendizaje profundo y redes neuronales, el campo ha podido dar grandes saltos en los últimos años y ha logrado superar a los humanos en algunas tareas relacionadas con la detección y etiquetado de objetos.
Uno de los factores impulsores detrás del crecimiento de la visión por computadora es la cantidad de datos que generamos hoy en día que luego se utilizan para entrenar y mejorar la visión por computadora.
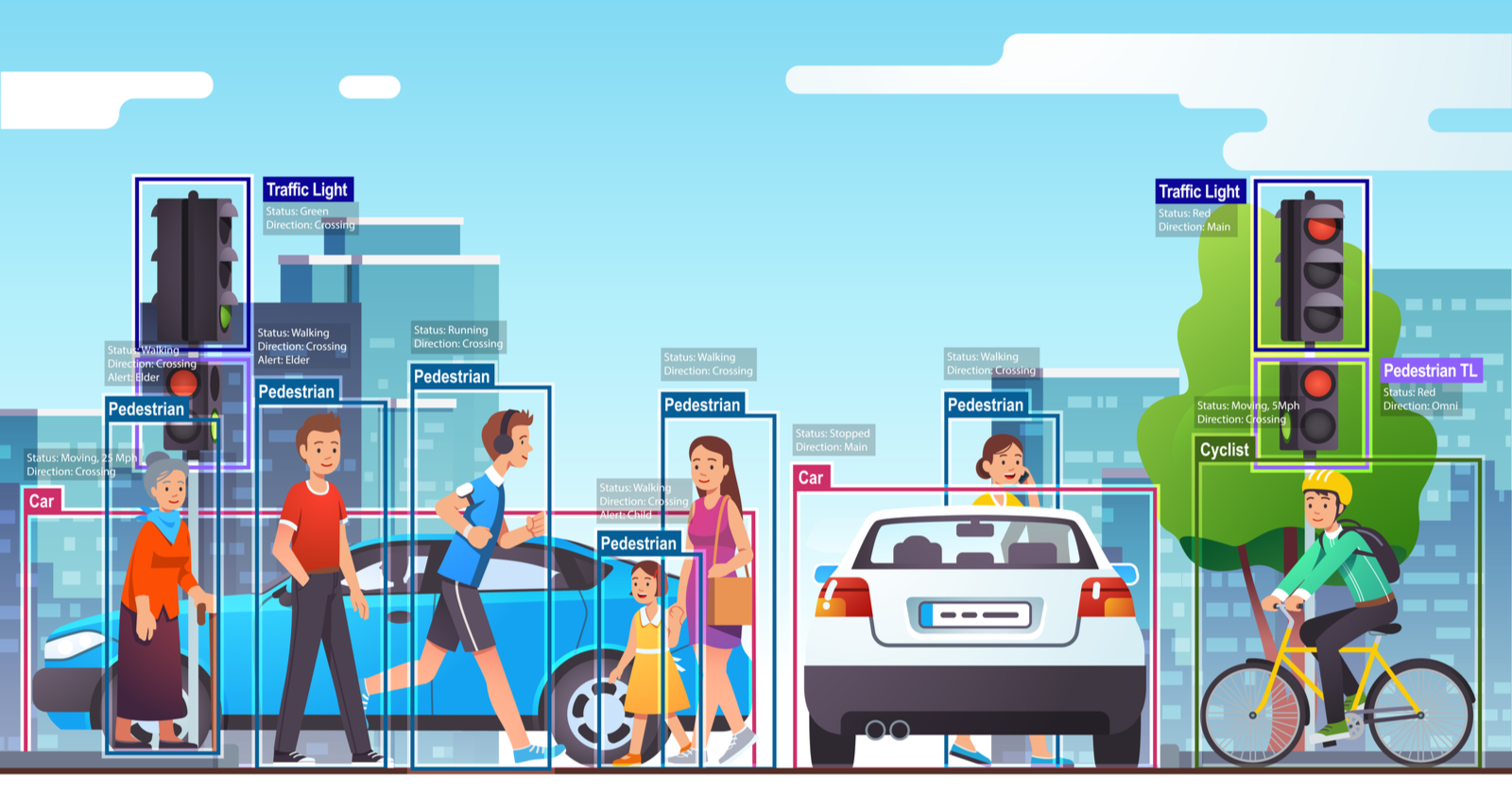
Esquema general del funcionamiento de la visión por computadora
Junto con una tremenda cantidad de datos visuales (más de 3 mil millones de imágenes se comparten en línea cada día), la potencia de cómputo necesaria para analizar los datos es ahora accesible. A medida que el campo de la visión por computadora ha crecido con nuevo hardware y algoritmos, también lo ha hecho la precisión en la identificación de objetos. En menos de una década, los sistemas actuales han alcanzado una precisión del 99 por ciento desde el 50 por ciento, haciéndolos más precisos que los humanos para reaccionar rápidamente a estímulos visuales.
Los primeros experimentos en visión por computadora comenzaron en la década de 1950 y se utilizó comercialmente por primera vez para distinguir entre texto mecanografiado y manuscrito en la década de 1970. Hoy en día, las aplicaciones para la visión por computadora han crecido exponencialmente.
Se espera que para 2024, el mercado de hardware y visión por computadora alcance los $48.6 mil millones de dólares.
¿Cómo funciona la visión por computadora?
Una de las principales preguntas abiertas tanto en Neurociencia como en Aprendizaje Automático es: ¿Cómo funciona exactamente nuestro cerebro y cómo podemos aproximar eso con nuestros propios algoritmos? La realidad es que hay muy pocas teorías funcionales y completas sobre la computación cerebral; así que a pesar de que se supone que las Redes Neuronales “imitan la forma en que funciona el cerebro”, nadie está muy seguro de si eso es realmente cierto.
La misma paradoja es cierta para la visión por computadora: dado que no hemos decidido cómo el cerebro y los ojos procesan las imágenes, es difícil decir qué tan bien los algoritmos utilizados en producción aproximan nuestros propios procesos mentales internos.
En cierto nivel, la visión por computadora se trata de reconocimiento de patrones. Entonces, una forma de entrenar a una computadora para que entienda los datos visuales es alimentarla con imágenes, muchas imágenes, miles, millones si es posible, que han sido etiquetadas, y luego someterlas a varias técnicas de software, o algoritmos, que permiten a la computadora buscar patrones en todos los elementos relacionados con esas etiquetas.
Por ejemplo, si alimentas a una computadora con un millón de imágenes de gatos (a todos nos encantan 😄😹), las someterás a algoritmos que le permitan analizar los colores en la foto, las formas, las distancias entre las formas, dónde los objetos limitan entre sí, y así sucesivamente, para que identifique un perfil de lo que significa “gato”. Cuando termine, la computadora podrá (en teoría) usar su experiencia si se le alimentan otras imágenes sin etiquetar para encontrar las que son de gatos.
Representación digital de imágenes
Dejemos a nuestros amigos felinos esponjosos por un momento a un lado y pongámonos más técnicos 🤔😹. A continuación, se muestra una ilustración simple del búfer de imagen en escala de grises que almacena nuestra imagen de Abraham Lincoln. El brillo de cada píxel está representado por un solo número de 8 bits, cuyo rango va de 0 (negro) a 255 (blanco):
Representación digital de una imagen en píxeles
Esta forma de almacenar datos de imagen puede ir en contra de tus expectativas, ya que los datos ciertamente parecen ser bidimensionales cuando se muestran. Sin embargo, este es el caso, ya que la memoria de la computadora consiste simplemente en una lista lineal cada vez mayor de espacios de dirección.
Estructura de almacenamiento de píxeles en memoria
Volvamos a la primera imagen nuevamente e imaginemos agregar una de color. Ahora las cosas comienzan a complicarse. Las computadoras generalmente leen el color como una serie de 3 valores: rojo, verde y azul (RGB) en esa misma escala de 0-255. Ahora, cada píxel tiene en realidad 3 valores para que la computadora almacene además de su posición. Si fuéramos a colorear al Presidente Lincoln, eso llevaría a 12 x 16 x 3 valores, o 576 números.

Representación de colores RGB en imágenes digitales
Esa es mucha memoria para requerir para una sola imagen, y muchos píxeles para que un algoritmo itere. Pero para entrenar un modelo con una precisión significativa, especialmente cuando se habla de Aprendizaje Profundo, normalmente necesitarías decenas de miles de imágenes, y cuantas más, mejor.
La Evolución de la Visión por Computadora
Antes del advenimiento del aprendizaje profundo, las tareas que la visión por computadora podía realizar eran muy limitadas y requerían mucha codificación manual y esfuerzo por parte de los desarrolladores y operadores humanos. Por ejemplo, si querías realizar reconocimiento facial, tendrías que seguir estos pasos:
Era Pre-Aprendizaje Profundo
Crear una base de datos: Tenías que capturar imágenes individuales de todos los sujetos que querías rastrear en un formato específico.
Anotar imágenes: Luego, para cada imagen individual, tendrías que ingresar varios puntos de datos clave, como la distancia entre los ojos, el ancho del puente de la nariz, la distancia entre el labio superior y la nariz, y docenas de otras medidas que definen las características únicas de cada persona.
Capturar nuevas imágenes: A continuación, tendrías que capturar nuevas imágenes, ya sea de fotografías o contenido de video. Y luego tendrías que pasar por el proceso de medición nuevamente, marcando los puntos clave en la imagen. También tenías que tener en cuenta el ángulo en que se tomó la imagen.
Después de todo este trabajo manual, la aplicación finalmente podría comparar las medidas en la nueva imagen con las almacenadas en su base de datos y decirte si correspondían con alguno de los perfiles que estaba rastreando. De hecho, había muy poca automatización involucrada y la mayor parte del trabajo se realizaba manualmente. Y el margen de error seguía siendo grande.
Era del Aprendizaje Automático
El aprendizaje automático proporcionó un enfoque diferente para resolver problemas de visión por computadora. Con el aprendizaje automático, los desarrolladores ya no necesitaban codificar manualmente cada regla en sus aplicaciones de visión. En su lugar, programaban “características”, aplicaciones más pequeñas que podían detectar patrones específicos en las imágenes. Luego usaban un algoritmo de aprendizaje estadístico como regresión lineal, regresión logística, árboles de decisión o máquinas de vectores de soporte (SVM) para detectar patrones y clasificar imágenes y detectar objetos en ellas.
El aprendizaje automático ayudó a resolver muchos problemas que históricamente eran desafiantes para las herramientas y enfoques clásicos de desarrollo de software. Por ejemplo, hace años, los ingenieros de aprendizaje automático pudieron crear un software que podía predecir las ventanas de supervivencia del cáncer de mama mejor que los expertos humanos. Sin embargo, construir las características del software requirió los esfuerzos de docenas de ingenieros y expertos en cáncer de mama y tomó mucho tiempo desarrollarlo.
Era del Aprendizaje Profundo
El aprendizaje profundo proporcionó un enfoque fundamentalmente diferente para hacer aprendizaje automático. El aprendizaje profundo se basa en redes neuronales, una función de propósito general que puede resolver cualquier problema representable a través de ejemplos. Cuando proporcionas a una red neuronal muchos ejemplos etiquetados de un tipo específico de datos, podrá extraer patrones comunes entre esos ejemplos y transformarlos en una ecuación matemática que ayudará a clasificar futuras piezas de información.
Por ejemplo, crear una aplicación de reconocimiento facial con aprendizaje profundo solo requiere que desarrolles o elijas un algoritmo preconstruido y lo entrenes con ejemplos de los rostros de las personas que debe detectar. Dados suficientes ejemplos (muchos ejemplos), la red neuronal podrá detectar rostros sin más instrucciones sobre características o medidas.
El aprendizaje profundo es un método muy efectivo para hacer visión por computadora. En la mayoría de los casos, crear un buen algoritmo de aprendizaje profundo se reduce a recopilar una gran cantidad de datos de entrenamiento etiquetados y ajustar los parámetros, como el tipo y número de capas de redes neuronales y épocas de entrenamiento. En comparación con tipos anteriores de aprendizaje automático, el aprendizaje profundo es más fácil y rápido de desarrollar e implementar.
La mayoría de las aplicaciones actuales de visión por computadora, como la detección de cáncer, los automóviles autónomos y el reconocimiento facial, utilizan el aprendizaje profundo. El aprendizaje profundo y las redes neuronales profundas han pasado del ámbito conceptual a las aplicaciones prácticas gracias a la disponibilidad y los avances en hardware y recursos de computación en la nube.
¿Cuánto tiempo se tarda en descifrar una imagen?
En resumen, no mucho. Esa es la clave de por qué la visión por computadora es tan emocionante: Mientras que en el pasado incluso las supercomputadoras podían tardar días, semanas o incluso meses en procesar todos los cálculos requeridos, los chips ultrarrápidos de hoy y el hardware relacionado, junto con una Internet rápida y confiable y redes en la nube, hacen que el proceso sea extremadamente rápido.
Un factor crucial ha sido la disposición de muchas de las grandes empresas que realizan investigaciones en IA para compartir su trabajo (Facebook, Google, IBM y Microsoft, notablemente) al hacer de código abierto parte de su trabajo de aprendizaje automático.
Esto permite a otros construir sobre su trabajo en lugar de empezar desde cero. Como resultado, la industria de la IA está avanzando rápidamente, y experimentos que no hace mucho tomaban semanas para ejecutarse podrían tomar 15 minutos hoy. Y para muchas aplicaciones del mundo real de la visión por computadora, este proceso ocurre continuamente en microsegundos, de modo que una computadora hoy es capaz de ser lo que los científicos llaman “situacionalmente consciente”.
Aplicaciones de la visión por computadora
La visión por computadora es una de las áreas del Aprendizaje Automático donde los conceptos básicos ya se están integrando en los principales productos que usamos todos los días.
Automóviles autónomos
Pero no son solo las empresas tecnológicas las que aprovechan el Aprendizaje Automático para aplicaciones de imágenes.
La visión por computadora permite a los automóviles autónomos dar sentido a su entorno. Las cámaras capturan video desde diferentes ángulos alrededor del automóvil y lo envían al software de visión por computadora, que luego procesa las imágenes en tiempo real para encontrar los extremos de las carreteras, leer señales de tráfico, detectar otros automóviles, objetos y peatones. El automóvil autónomo puede entonces dirigirse en calles y carreteras, evitar chocar con obstáculos y (con suerte) conducir de manera segura a sus pasajeros a su destino.
Reconocimiento facial
La visión por computadora también juega un papel importante en las aplicaciones de reconocimiento facial, la tecnología que permite a las computadoras hacer coincidir imágenes de rostros de personas con sus identidades. Los algoritmos de visión por computadora detectan características faciales en imágenes y las comparan con bases de datos de perfiles de rostros. Los dispositivos de consumo utilizan el reconocimiento facial para autenticar las identidades de sus propietarios. Las aplicaciones de redes sociales utilizan el reconocimiento facial para detectar y etiquetar a los usuarios. Las agencias de aplicación de la ley también confían en la tecnología de reconocimiento facial para identificar criminales en transmisiones de video.
Realidad Aumentada y Realidad Mixta
La visión por computadora también juega un papel importante en la realidad aumentada y mixta, la tecnología que permite a los dispositivos informáticos como smartphones, tabletas y gafas inteligentes superponer e incrustar objetos virtuales en imágenes del mundo real. Utilizando la visión por computadora, los equipos de RA detectan objetos en el mundo real para determinar las ubicaciones en la pantalla de un dispositivo donde colocar un objeto virtual. Por ejemplo, los algoritmos de visión por computadora pueden ayudar a las aplicaciones de RA a detectar planos como superficies de mesas, paredes y pisos, una parte muy importante para establecer la profundidad y las dimensiones y colocar objetos virtuales en el mundo físico.
Cuidado de la salud
La visión por computadora también ha sido una parte importante de los avances en la tecnología de la salud. Los algoritmos de visión por computadora pueden ayudar a automatizar tareas como la detección de lunares cancerosos en imágenes de la piel o encontrar síntomas en radiografías y resonancias magnéticas.
Desafíos de la visión por computadora
Ayudar a las computadoras a ver resulta ser muy difícil.
Inventar una máquina que vea como nosotros es una tarea engañosamente difícil, no solo porque es difícil hacer que las computadoras lo hagan, sino porque no estamos completamente seguros de cómo funciona la visión humana en primer lugar.
Estudiar la visión biológica requiere una comprensión de los órganos de percepción como los ojos, así como la interpretación de la percepción dentro del cerebro. Se ha logrado mucho progreso, tanto en el mapeo del proceso como en términos de descubrir los trucos y atajos utilizados por el sistema, aunque como cualquier estudio que involucre al cerebro, hay un largo camino por recorrer.
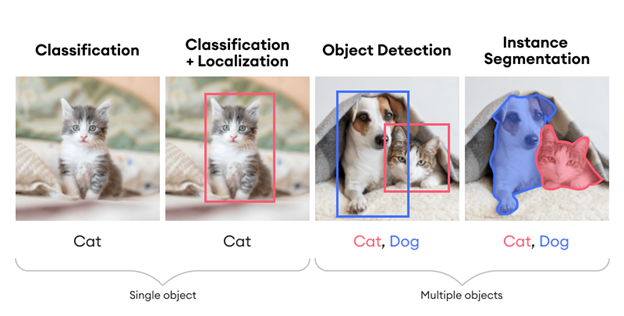
Principales tareas en visión por computadora
Tareas principales de reconocimiento
Muchas aplicaciones populares de visión por computadora implican tratar de reconocer cosas en fotografías; por ejemplo:
- Clasificación de objetos: ¿Qué categoría amplia de objeto está en esta fotografía?
- Identificación de objetos: ¿Qué tipo específico de un objeto dado está en esta fotografía?
- Verificación de objetos: ¿Está el objeto en la fotografía?
- Detección de objetos: ¿Dónde están los objetos en la fotografía?
- Detección de puntos clave de objetos: ¿Cuáles son los puntos clave del objeto en la fotografía?
- Segmentación de objetos: ¿Qué píxeles pertenecen al objeto en la imagen?
- Reconocimiento de objetos: ¿Qué objetos hay en esta fotografía y dónde están?
Otros métodos de análisis
Más allá del simple reconocimiento, otros métodos de análisis incluyen:
- El análisis de movimiento en video utiliza la visión por computadora para estimar la velocidad de los objetos en un video, o de la propia cámara.
- En la segmentación de imágenes, los algoritmos dividen las imágenes en múltiples conjuntos de vistas.
- La reconstrucción de escenas crea un modelo 3D de una escena introducida a través de imágenes o video.
- En la restauración de imágenes, se elimina el ruido, como el desenfoque, de las fotos utilizando filtros basados en Aprendizaje Automático.
Cualquier otra aplicación que implique la comprensión de píxeles a través de software puede etiquetarse con seguridad como visión por computadora.
Conclusión
A pesar del progreso reciente, que ha sido impresionante, todavía no estamos ni siquiera cerca de resolver la visión por computadora. Sin embargo, ya hay múltiples instituciones de salud y empresas que han encontrado formas de aplicar sistemas de CV, impulsados por CNN (Redes Neuronales Convolucionales), a problemas del mundo real. Y es probable que esta tendencia no se detenga pronto.
La visión por computadora continuará evolucionando y transformando industrias enteras, desde la medicina hasta el transporte, pasando por el entretenimiento y la seguridad. A medida que los algoritmos se vuelven más sofisticados y el poder de procesamiento aumenta, podemos esperar ver aplicaciones aún más innovadoras que cambien la forma en que interactuamos con el mundo digital y físico.
El futuro de la visión por computadora promete ser tan emocionante como desafiante, y estar al tanto de estos desarrollos será crucial para cualquier persona interesada en el campo de la inteligencia artificial y sus aplicaciones prácticas.
